5 minute read time
The Golden Ratio for Effective Email A/B Split Testing

Article first published April 2014, updated January 2019.
One of Campaign Monitor’s strengths is the ability to test versions of your email campaign on a subset of your subscriber list. Many call this A/B testing, but in some circles, this is known as split testing, or even 10/10/80. We regularly get asked about how to set up accurate tests on subject lines, content or from details, so here are my thoughts on how regular senders—and not just statisticians—can do this.
Why should I A/B test my email content?
A/B split testing is the best way to understand the types of content your subscribers are most likely to engage with. To put it simply, you don’t know what they like unless you ask them, but instead of asking them directly and generally, A/B testing is a tool that essentially asks, “This or that?.” These are the kind of questions you can answer using A/B testing:
- Do your subscribers prefer a personalized subject line or one that advertises a coupon code?
- Is your audience more likely to enjoy a picture of a beach or a mountain scene?
- Would your readers be more likely to open an email from your company’s name or a personal message from your CEO?
Running an A/B test in Campaign Monitor
When asked the question, “How many people should I be running an A/B test on?”, the honest response is that it varies. But as we don’t like to leave our readers and customers in such a state of uncertainty, I’m going to share a quick and easy way to calculate an effective sample size for your A/B test campaign.
Making a statistically significant difference
Life is better with shortcuts, so to keep you from having to learn statistics from the ground up, we use Evan Miller’s excellent Sample Size Calculator tool to determine our optimal sample size.
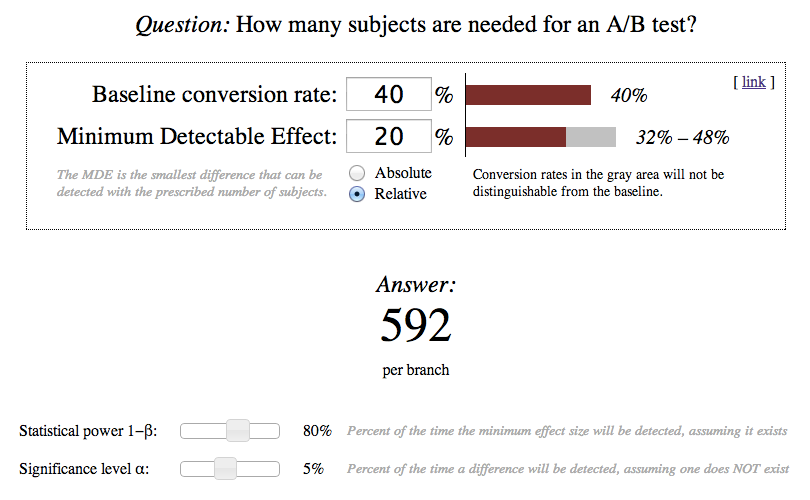
Unless you have a rather advanced understanding of how testing works, much of the above may seem very unfamiliar to you. So, let’s look into what each of the calculator’s variables represents:
Baseline conversion rate
This is what your average campaign performance is in terms of open or click rates. Let’s say that on average, 40% of your emails are opened, so your baseline conversion rate would be 40%. Here’s how to get the average open and/or click rates for your campaigns.
Minimum detectable effect
Think of Minimum Detectable Effect (MDE) as your improvement/regression threshold, or the smallest difference that you want to detect from your campaign test. Using the 40% open rate from above, a relative MDE of 20% would mean that any open rate that fell inside of 32% – 48% would not be distinguishable from the baseline. Anything outside of this range would be considered a detectable change in your open rate.
Absolute vs. Relative MDE can mean a big difference in your sample size, so make sure you have the right option selected.
Statistical power and significance level
Statistical power is the probability that there will be a false negative, so a setting of 80% indicates that there is a 20% chance that you would miss the effect altogether.
Significance level indicates the chance of a false positive, so at a setting of 5%, there is only a 5% chance that you would see a change in effect when in fact there wasn’t one.
These two options are down at the bottom of the calculator for a reason, as they should be left at their set values for the vast majority of users. Researchers have settled on these numbers as adequate for their tests, and my advice is that so should you.
Once you’ve plugged in your baseline conversion rate and your MDE, you’ll be presented with a number in the “Answer” section. This is how many subscribers/contacts on your list should receive each version of the AB test campaign. So using the example inputs above, we would need each version of the campaign to be sent to 592 subscribers, or 1,184 in total, for this to be deemed an accurate A/B test.
Testing smaller email sends
The lower your open rate, the more subscribers you’ll need to run an accurate test.”Now, you may be thinking, “My list size is only 500 subscribers, how do you expect me to run a successful test?” My answer is that you’ll need to set your sights on a larger MDE. When you increase the MDE, your required sample size decreases. So instead of needing 592 subscribers per variation to detect a 20% relative effect, you would only need 94 subscribers per variation to detect a 50% relative effect. Note that the baseline conversion rate also plays a part in your sample size – the lower your conversion rate (in this case, open %), the more subscribers you’ll need to run an accurate test.
With your sample size number in hand, you’re now ready to define your test settings, line up your content and launch your A/B test campaign. There is one small caveat in that you must select how long your test should run for – I recommend setting this to at least 1 day, to allow for a majority of your subscribers to see the email.
Finally, whether you’re sending to a list size of 500 or 500,000, the benefits of A/B testing can’t be ignored, and with the right sample size in place, you’ll have an accurate measure of how successful your email optimization efforts can be. Whether it’s determining the ideal subject line to drive opens, the best “from” name to instill trust and familiarity, or the content of the email itself to encourage more clicks, A/B testing can only result in positive outcomes for your business.
Hopefully after reading this, you’ll feel more confident and informed to run your own A/B test. If you’re ready to begin sending emails through Campaign Monitor’s easy-to-use platform with intuitive A/B testing tools, request a demo today.




